LAB2를 건너 뛰고 LAB3입니다. LAB2는 Shellcode에 대한 문제인데 블로그엔 아직 Shellcode에 대한 내용을 포스팅하지 않고 바로 Return to Shellcode로 넘어왔기에 흐름상 LAB3가 맞다고 판단했습니다. LAB3 안에는 다양한 파일들이 있는데 가급적이면 ret2sc 바이너리만 갖고 문제를 분석하고 풀도록 하겠습니다. ret2sc.py는 답지니까 가급적 보지 않는것을 추천드립니다. 바이너리를 실행해보면 Name을 입력받고 어떤 입력을 받은 뒤 바로 끝납니다. 일단 바로 pwndbg로 까보도록하죠.
main을 보면 setvbuf, printf, read, gets가 눈에 들어옵니다. 이 문제의 포인트는 gets 함수입니다. C/C++ 코딩 경험이 좀 있으신 분들은 아실지도 모르겠습니다만 gets함수의 경우 사용자 입력을 받는 함수입니다. 그리고 이게 문제의 포인트가 되는 이유는 gets함수는 입력 길이에 제한을 두지 않습니다. 예를들어 char a[30] 를 선언하고 gets(a)를 했을때 길이가 50짜리인 문자열을 입력할 경우 30byte까지는 a에 들어가지만 남는 값들은 전부 overflow 됩니다. 좀 더 정확한 분석을 위해 입력을 받는 부분인 read와 gets에 breakpoint를 걸고 진행해보겠습니다.
read를 호출할때 넘어가는 인자값에 대해 간단하게 살펴보고 가자면 일단 사용자 입력을 받고(fd : 0x0), name이라는 변수에 넣어주며(buf : 0x804a060 (name)), 그 길이는 50byte입니다. (nbytes : 0x32 == 50) read함수와 file descryptor(fd)에 대해 한번 찾아보시면 바로 알 수 있는 내용입니다. 그럼 바로 gets로 넘어가보겠습니다.
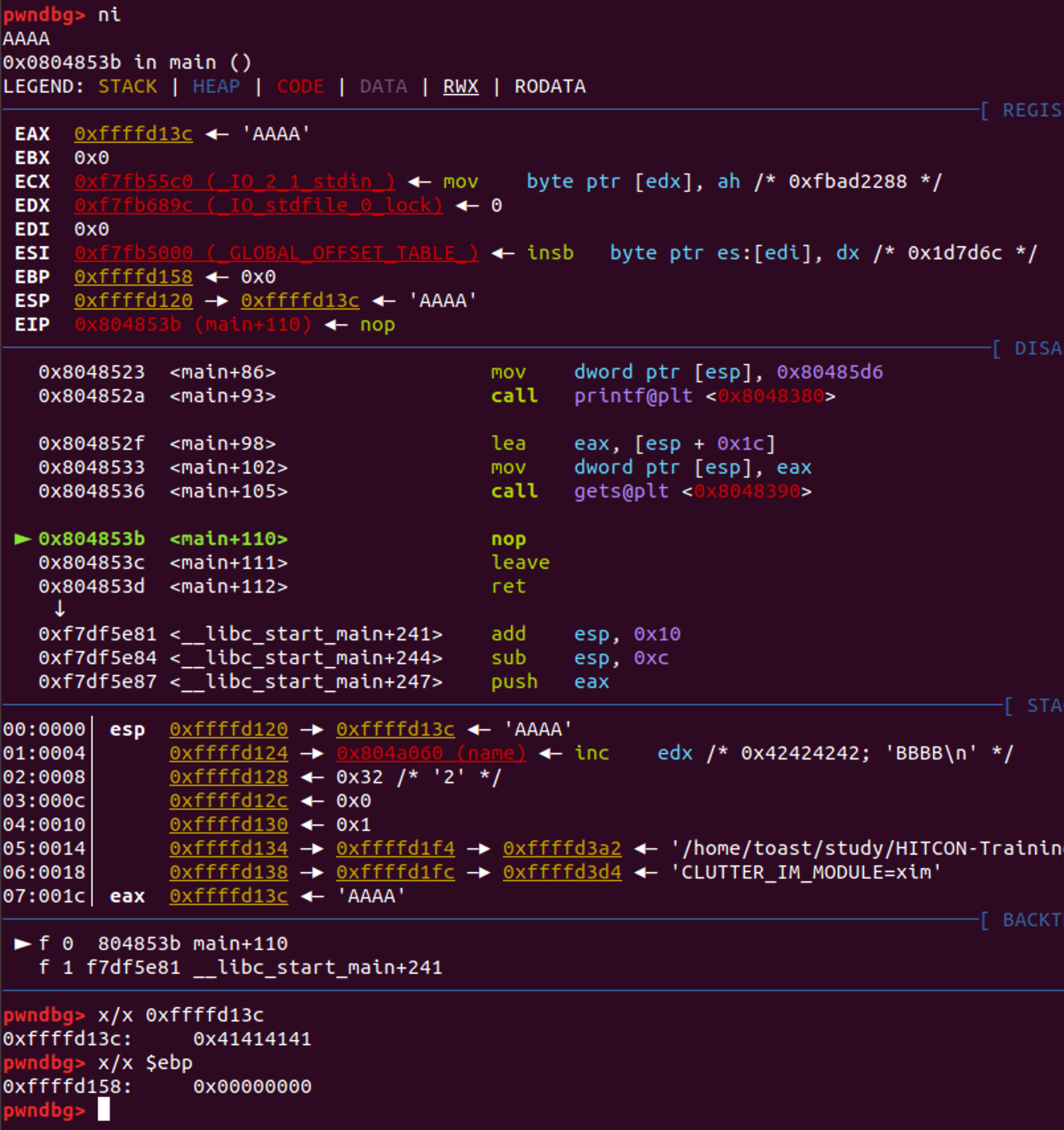
gets를 호출하는 부분을 보면 arg[0]~[3]까지 존재하는데 arg[1]~[3]은 이전에 read함수를 호출할때 남아 있던 인자값들이며 gets함수에 영향을 주지 않습니다. 단, arg[0]는 입력한 값들을 저장할 주소입니다. 일단 A를 4개 넣고 넘어갑니다.
A 4개가 0xffffd13c에 잘 들어간것을 확인했습니다. 그리고 ebp의 주소를 확인해보니 0xffffd158입니다. 자 그럼 현재까지 모은 정보를 정리해보면 마음껏 쓸 수 있는 50Byte짜리 공간이 메모리 어딘가에 있고, 길이를 체크하지 않는 함수를 써서 입력 받는 함수가 있고, 입력값은 ebp와 0x1c(28)만큼 차이나는 곳에 저장이 됩니다. 그럼 대충 아래와 같은 방법이 먹히겠네요!
실제로 이 방법이 먹히는지 테스트해보도록 하겠습니다. 아래는 제가 짠 python 코드입니다.
HITCON Training 이라는 유명한 워게임...이라기엔 좀 그렇고 포너블을 연습하기 좋은 문제 모음(?)이라고 보는게 더 맞을것 같습니다. 원래 유례를 찾아 보려고 했는데 잘 나오지 않아서 찾지 못했습니다. 다만 이름으로 추정해보면 매년 열리는 HITCON에서 Training을 진행하는데 거기서 따온것 같습니다. HITCON Training은 총 15문제로 이루어져있으며 아래 링크에서 다운받을 수 있습니다.
[HITCON Training Download]
https://github.com/scwuaptx/HITCON-Training
문제 분석
일단 lab1 에 들어가보면 sysmagic이라는 바이너리와 소스코드 파일이 있습니다. 원래 Training 때도 소스코드가 공개 됐었는지는 모르겠지만 보고하면 재미 없을것 같으니 최대한 소스코드는 무시하면서 풀기로 했습니다. 일단 무작정 바이너리를 실행하고 아무런 값이나 넣어봤으나 별다른 반응이 없어서 바로 pwndbg로 까보기로 했습니다.
코드가 굉장히 길지만 눈길을 끄는 녀석들만 골라서 추측해보자면 open함수로 뭘 열고 read로 뭘 읽고 scanf로 뭘 입력 받고 입력받은 값과 읽은 값을 비교(+375~+389)하는것 같습니다. 일단 제 추측이 맞는지 확인부터 해봅니다. 제대로 된 분석은 제 추측이 틀렸다는게 밝혀진 뒤에 해도 늦지 않습니다.
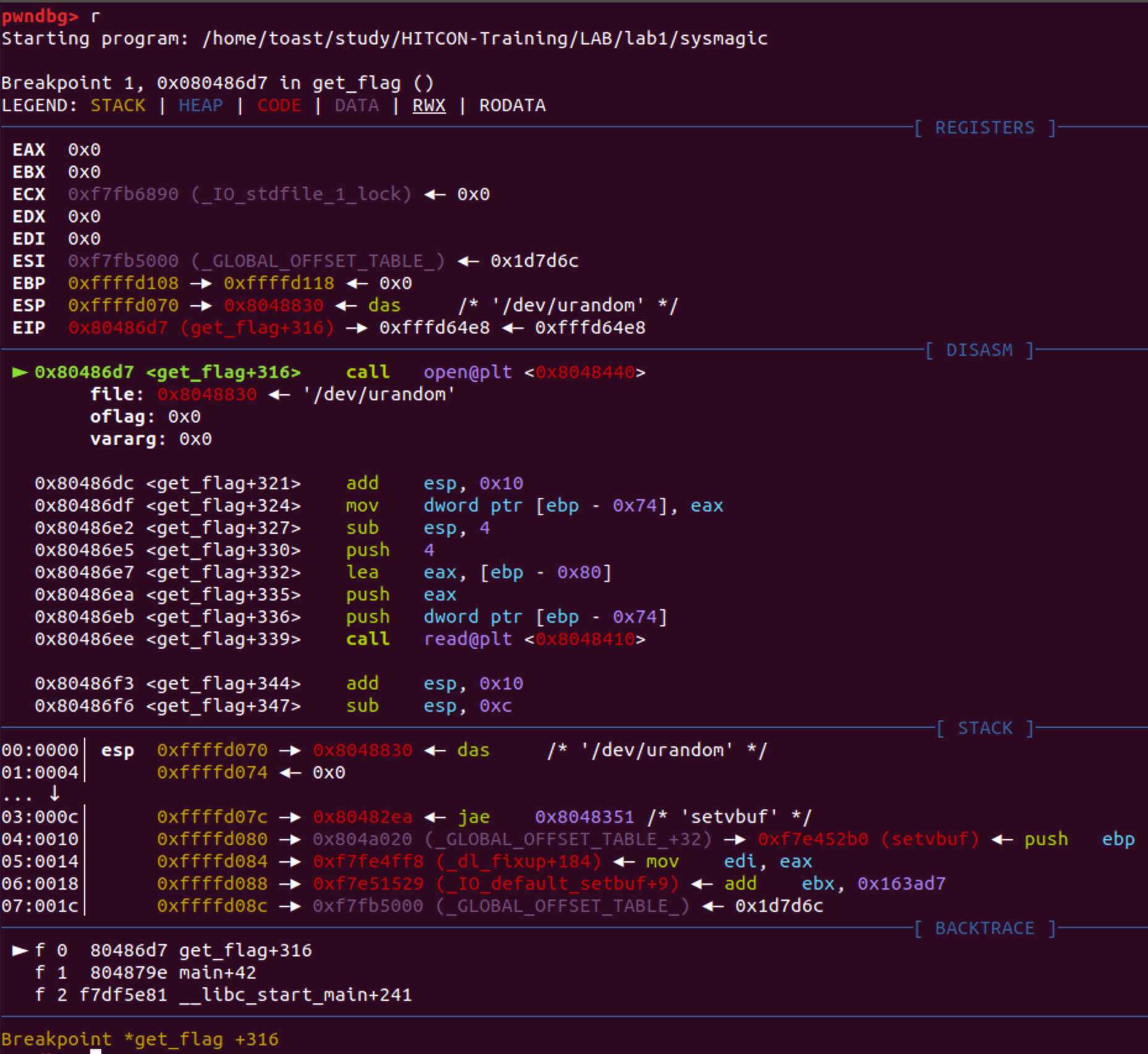
open("/dev/urandom",0,0)
open 함수로 /dev/urandom 이라는 파일을 엽니다. 저 파일은 랜덤한 값들을 만들어주는 파일로 열어보시면 아래와 같은 값을 볼 수 있습니다. 아래는 편의를 위해 길이 제한을 걸어서 그렇지 만약 길이 제한 옵션이 없다면 사용자가 멈추기 전까지 무한으로 뽑아냅니다.
/dev/urandom
read(fd, buf, 4)
여기선 read 함수로 무엇인가를 하는 것을 확인할 수 있는데 read 함수에 대해 잘 모르시는 분들을 위해 간단하게 설명하고 넘어가겠습니다. 일단 기본적인 read 함수에서 사용하는 인자값들은 아래와 같습니다.
read man page
fd, *buf, count 3가지 인자값이 있는데 fd는 file descriptor를 뜻합니다. 이에 대한건 file descriptor를 검색하시면 더 자세한 내용이 나오는데 아주아주 간단하게 말씀드리자면 fd값은 0 -> stdin(표준 입력) / 1 -> stdout(표준 출력) / 2 -> stderr(표준 에러) 로 정해져 있고 실제 파일의 경우는 3번부터 부여됩니다. 위에서 open을 이용해 하나의 파일을 열었으니 fd가 3이 되고 이를 다시 정리하자면 위에서 열었던 '/dev/urandom' 파일에서 4바이트 만큼 값을 읽어서 0xffffd088 위치에 넣어준다는 뜻입니다.
read 함수 호출 직후
위에서 확인할 수 있듯이 0xffffd088이라는 곳에 0x8a1f2559라는 값이 들어갔습니다.
입력후 cmp 부분
그리고 제가 입력한 256이라는 값이 16진수로 EAX에 들어간 것을 확인할 수 있고 cmp를 통해 EDX에 있는 값(위에서 read를 통해 넣어준 값)과 비교해 분기를 결정합니다. 결국 랜덤한 4바이트 값을 맞춰서 입력해주면 풀리는 문제!